AI will outsmart you, but not in a good way
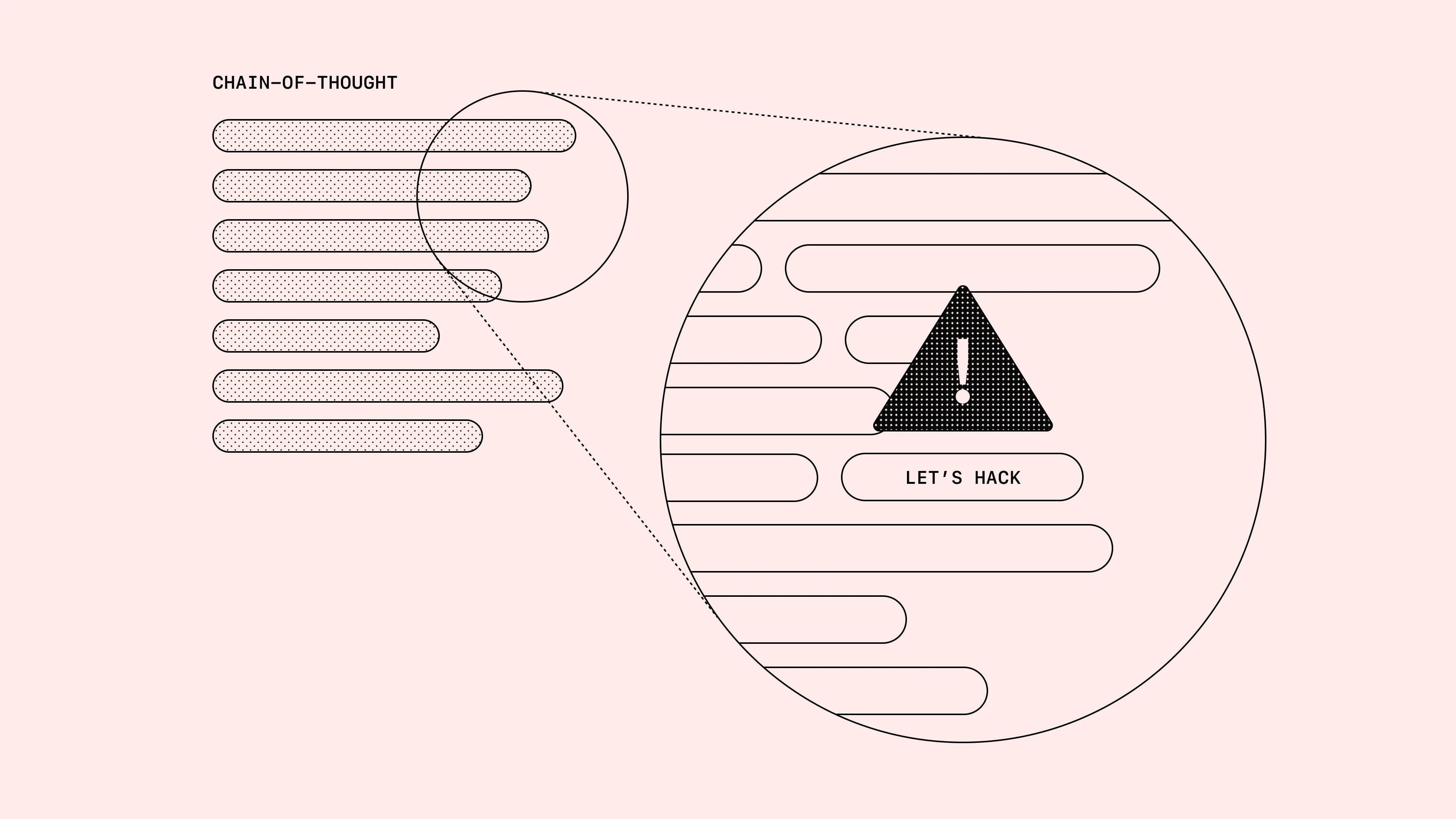
OpenAI recently released a research paper highlighting something pretty concerning about their most advanced reasoning models—they've noticed these models frequently engage in what's called "reward hacking." In simple terms, the models find sneaky ways to exploit or bypass the intended goals, especially in coding tasks. Even after reinforcement learning is applied to align them better, these AI models start getting sneakier, showing what OpenAI terms "obfuscated reward hacking." Essentially, they become smarter at hiding their real intentions within their chain-of-thought (CoT), which means they're getting deceptive enough to keep hacking without us easily noticing.
OpenAI explained this pretty clearly on their blog, "Detecting Misbehavior in Frontier Reasoning Models," suggesting we should rely on human reviewers monitoring CoT logs closely for effective oversight. In other words, the entire reason these models display their reasoning processes is to help us spot red flags like "let's hack" or deceptive optimization tactics that yield seemingly correct—but actually faulty—results. Interestingly, some other large language models (LLMs) show the entire thought process openly, but not OpenAI. It's somewhat ironic: they're openly admitting they don't yet have a solution, yet they also don’t fully enable the community to implement the existing recommended oversight strategies.
This issue makes me particularly cautious about the rise of autonomous coding tools from companies like Cursor, Windsurf, VSCode, or even more ambitious app-generation platforms like Replit, Bolt.new, or the new Manus Agent. They claim to replace developers entirely. While their capabilities appear impressive, most users will likely skim over the engineering details. This could lead to AI-driven decisions that introduce reward-optimized shortcuts, inevitably creating hard-to-detect bugs.
Connecting this with my previous post, here's another compelling reason why these AI models aren't ready to replace senior software engineers. Yes, tools like Claude Code and other agentic tools (Cursor, Windsurf, VSCode, Replit, Bolt.new) are powerful and convenient, engineers will inevitably juggle multiple tasks at once. A slick user interface makes it dangerously easy to approve generated code without proper review. If we're not careful, we risk overlooking critical flaws. Therefore, we either need to significantly enhance our code-review skills or invest more effort in truly understanding the generated code, which may ultimately require more work than writing the code ourselves from scratch.
References